我们如何在 Gradle 中处理不稳定的测试
引言
测试不稳定性是自动化测试面临的主要挑战之一。尽管 Gradle 的重点是提高开发人员的工作效率,但 Gradle 本身的发展也受到不稳定的自动化测试的困扰。这篇博客解释了在开发 Gradle 时的一些最佳实践,这些实践在多年与不稳定测试的斗争中被证明是有效的。
故事 #
与许多其他项目一样,Gradle 的每次提交都必须通过数万个自动化测试。任何微小的波动都可能导致开发人员生产力的损失。五年前我加入 Gradle 时,CI 中充斥着不稳定的测试失败——人们会一遍又一遍地重新运行构建,希望足够幸运地获得一个绿色的构建。
后来,我们成立了一个专门的开发人员生产力团队来处理 CI 上的所有不稳定性,尤其是测试不稳定性。以下是我们的分步做法。
重试失败的测试 #
当一个测试失败时,我们如何判断它是否不稳定?最简单的方法显然是立即重试失败的测试:如果第二次运行成功,那么失败的测试就是不稳定的。根据经验,只需再运行一次失败的测试,由于不稳定造成的测试失败就可以减少 90%。
许多 CI 系统可以识别此类不稳定测试并自动将构建标记为绿色
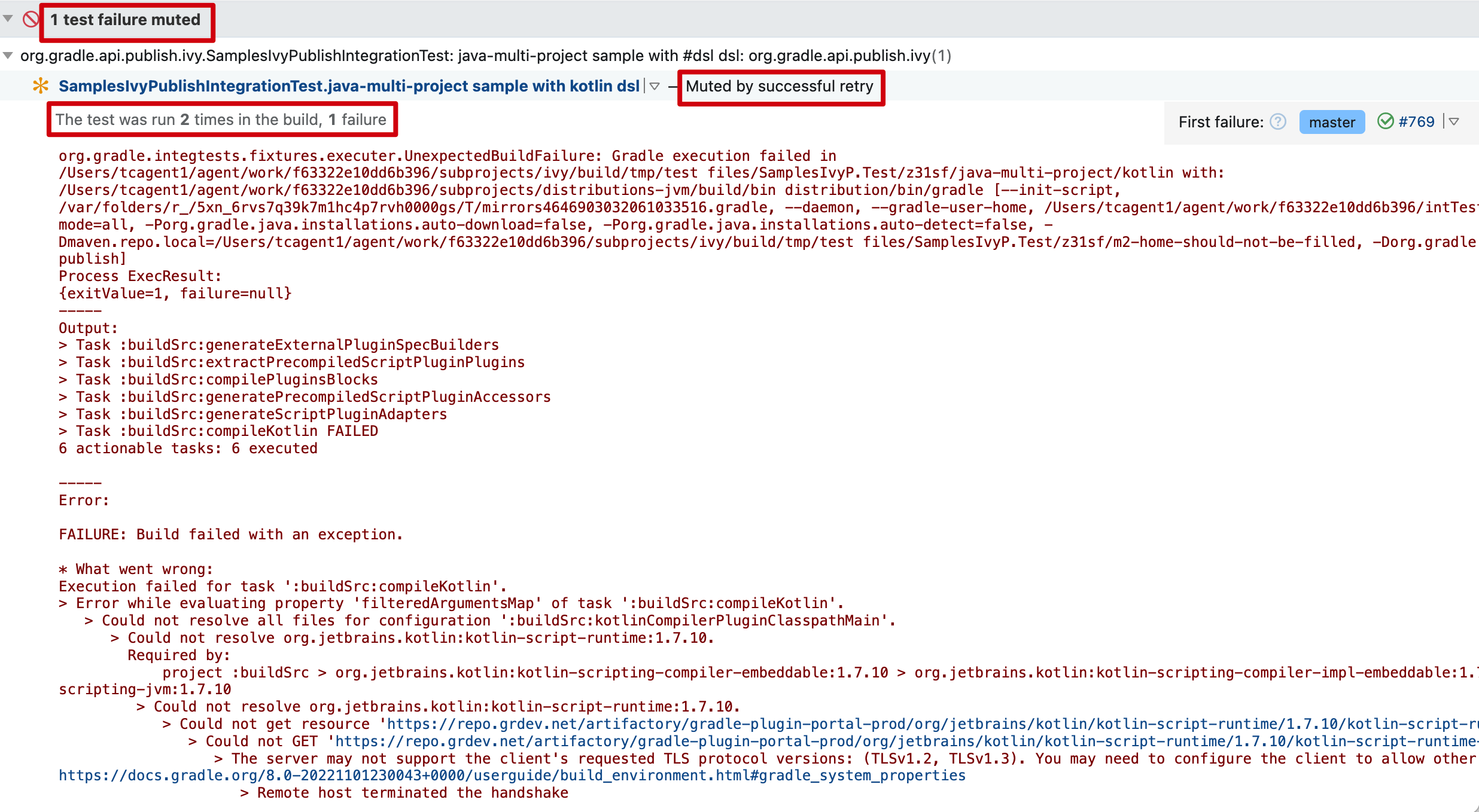
在此示例中,第一次运行因网络错误而失败,但重新运行成功。TeamCity 识别这种情况并“静默”测试失败。
如果构建连接到 Gradle Enterprise 实例并且该构建已发布 Build Scan,您可以在测试仪表板中查看不稳定的测试
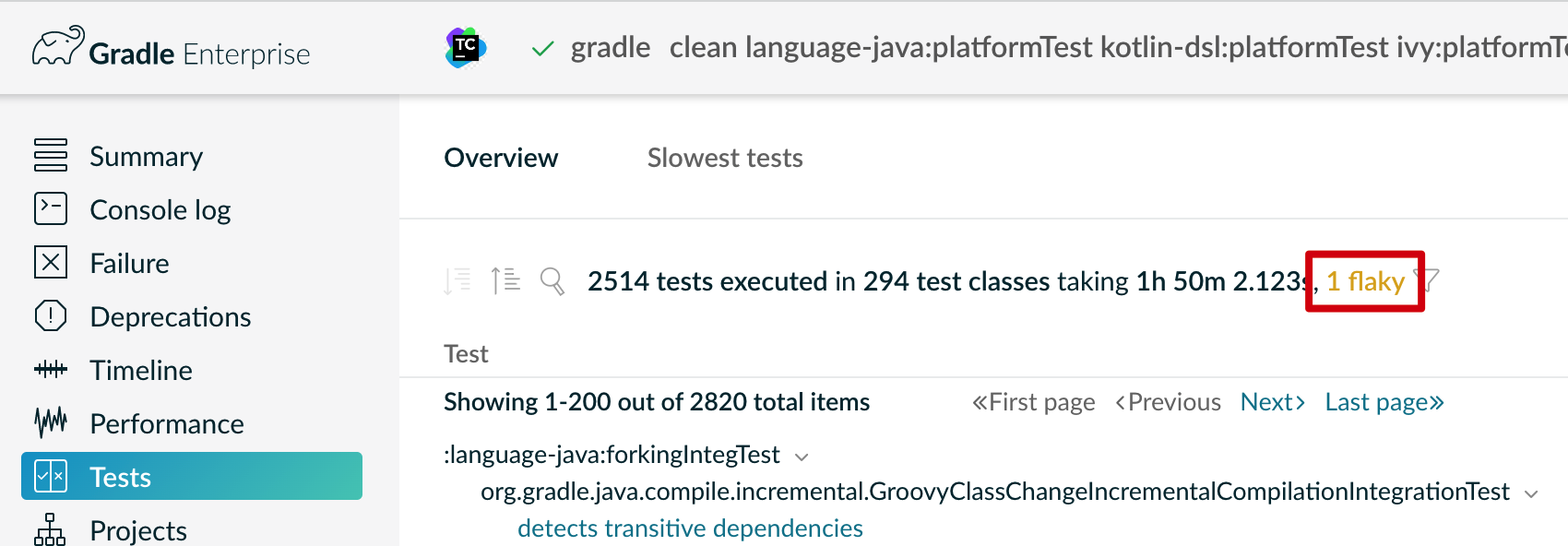
在 Gradle 中,我们使用 Test Retry Gradle 插件自动重试失败的测试类。有关如何在构建中采用它的信息,请查阅文档。
重试失败测试的其他技术 #
如果您不使用 Gradle,那也没关系。有许多替代方案提供类似的功能
上述所有工具都受 Gradle Enterprise 不稳定测试检测支持,它提供了很棒的 测试失败分析功能,可帮助您诊断测试不稳定性。
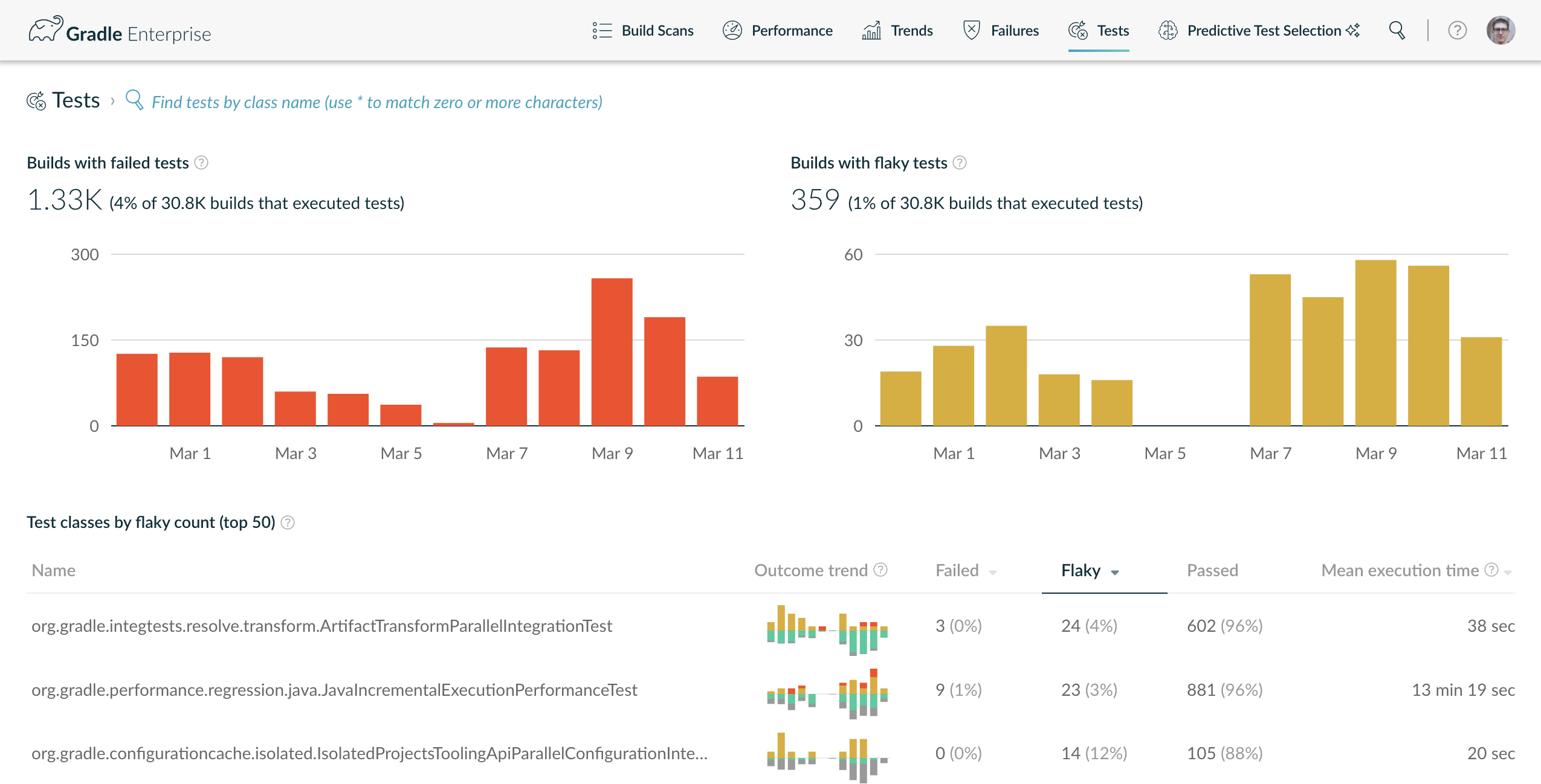
通过不稳定测试仪表板,您可以浏览不稳定测试用例或类的趋势和历史记录。这在排除不稳定测试的故障时非常有帮助。
隔离过度不稳定的测试 #
重试失败的测试就足够了吗?不幸的是,答案是否定的。Gradle 代码库中的一些测试非常不稳定,有时即使重试两次或更多次也会失败。这些不稳定测试通常是由有缺陷的生产代码或测试基础设施引起的,严重损害了开发人员的生产力。
在 Gradle 中,当我们发现此类“过度不稳定”的测试时,我们会将其隔离。隔离意味着这些测试与 CI 管道隔离,以获取开发人员反馈。换句话说,它们从开发人员的视线中消失,不再阻碍开发人员。
它们去哪儿了?我们是否丢失了这些“过度不稳定”测试的测试覆盖率?不,它们被收集并在每日 CI 作业中执行(我们称之为 Flaky Test Quarantine),每天运行一次,像这样
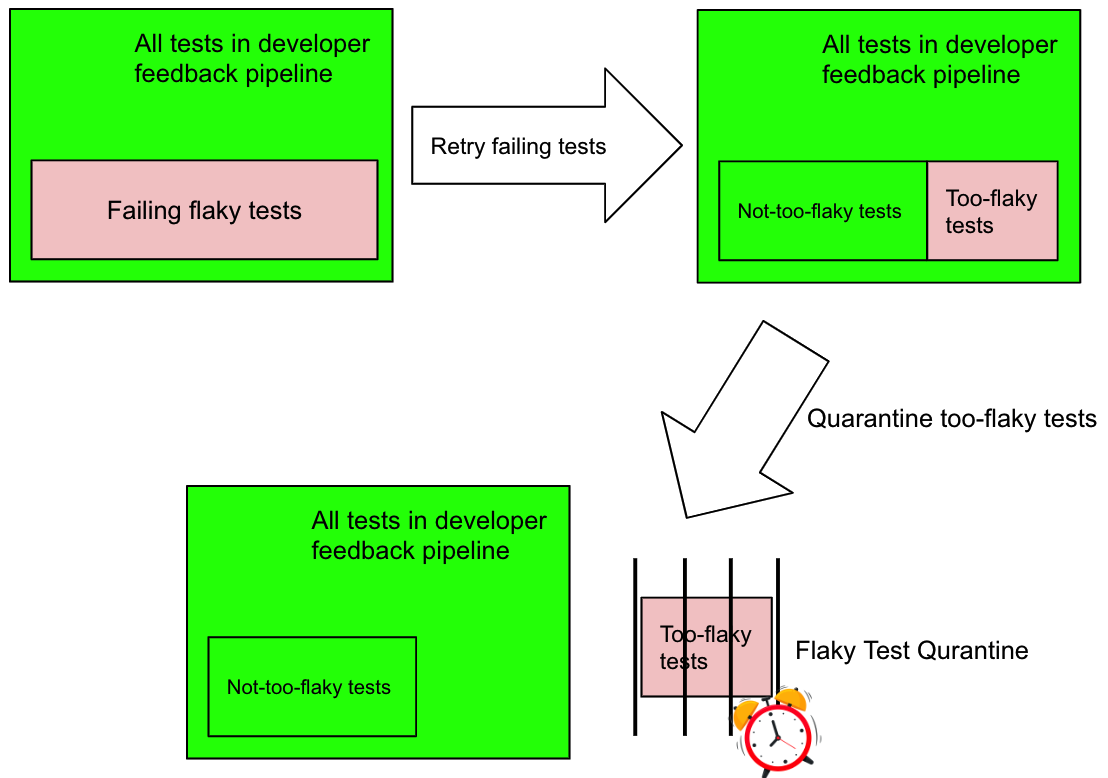
“过度不稳定”的测试通过手动向测试类或方法添加自定义 @Flaky 注解来隔离,一旦我们看到任何发生。我们还引入了 三种策略来选择要运行的测试
EXCLUDE:选择所有测试,不包括@Flaky测试。这是正常 CI 管道的默认策略。ONLY:仅选择@Flaky测试运行。这是Flaky Test Quarantine作业的策略。INCLUDE:选择所有测试,包括@Flaky测试运行。
(有关如何使用不同测试框架实现这些策略,请参阅 @Flaky 注解中的 Javadoc。)
修复不稳定的测试 #
上面的一切都不能**解决**不稳定测试中的真正问题——它只会**隐藏**问题并给你一种虚假的安全感。必须采取行动修复有缺陷的代码,即不稳定测试的根本原因。
得益于 Gradle Enterprise 不稳定测试检测功能中的测试仪表板,我们可以轻松地
- 计算所有不稳定测试的数量。
- 按发生频率对所有不稳定测试进行排序。
- 浏览特定不稳定测试的历史记录。这很重要,因为我们可以轻松识别引入不稳定测试的人。
我们每周审查所有不稳定测试一次,并采取行动将它们的总数保持在尽可能低的水平。以下是我们进行审查的方式
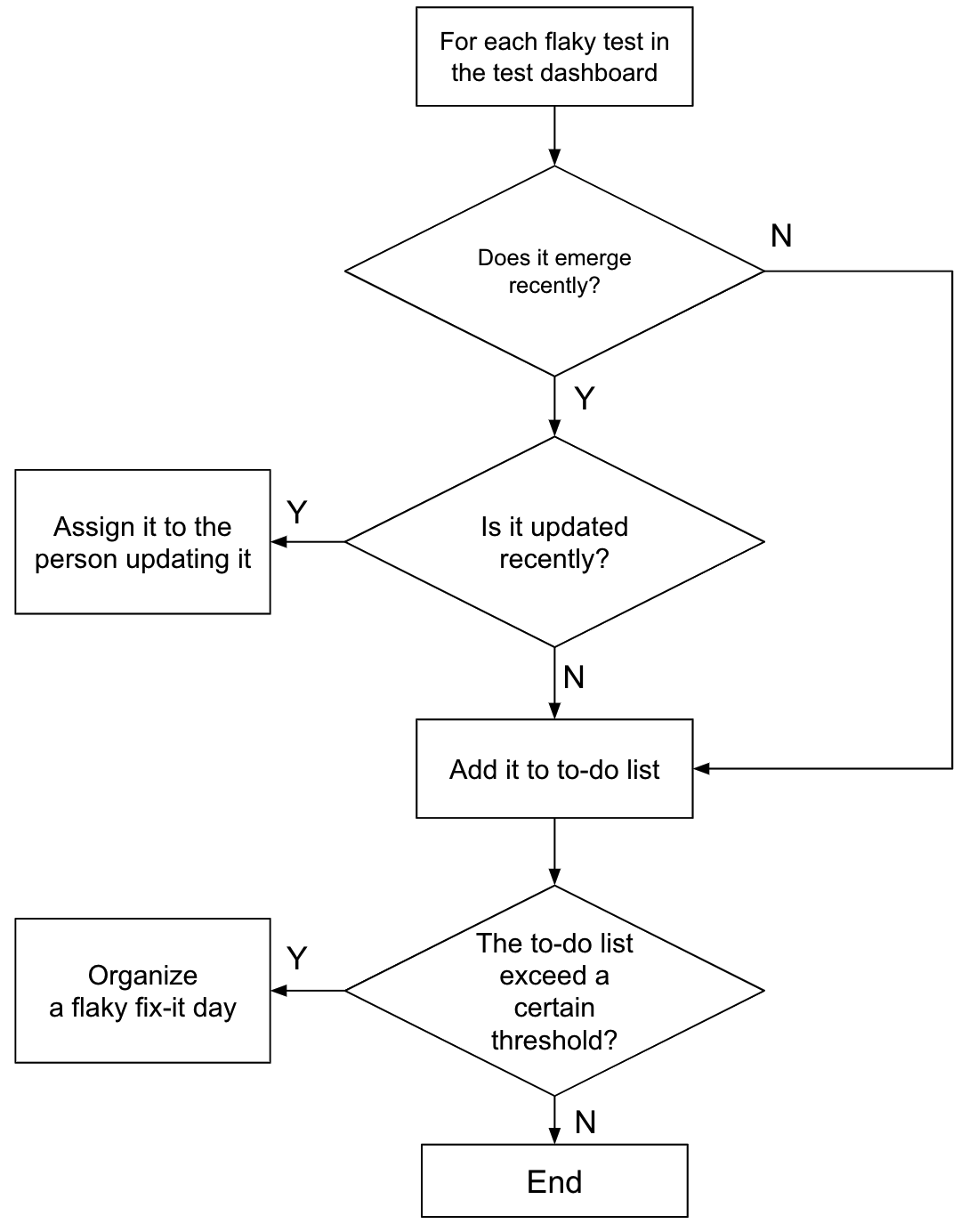
通过这种方式,大多数新的不稳定测试都会立即被发现并分配。无法分配的不稳定测试将被收集并在“不稳定修复日”修复。“不稳定修复日”是我们组织的一次为期 1 或 2 天的黑客马拉松,当不稳定测试数量超过某个阈值(例如,占测试总数的 1%)时,我们就会组织这次活动。在不稳定修复日,所有开发团队通力合作,专注于修复累积的不稳定测试。
总结 #
不稳定的测试令人痛苦,但可以采取措施防止它们损害开发人员的生产力。这篇博客描述了我们在 Gradle 开发中为控制不稳定测试所采取的措施:重试所有失败的测试,隔离过度不稳定的测试,并通过团队合作修复不稳定的测试。
反馈 #
如果您有任何问题,请在我们的论坛或Gradle 社区 Slack上告知我们。